



TABLE OF CONTENTS
Experience the Future of Speech Recognition Today
Try Vatis now, no credit card required.
You probably have a French recording sitting in a shared drive right now. It might be a customer interview, a webinar, a call-center escalation, a legal deposition, or a newsroom clip that an English-speaking team needs to review fast.
The trap is assuming this is a simple “upload audio, get English” task. For casual listening, that can be enough. For anything operational, regulated, or publishable, it usually isn't. The work doesn't end when the model produces readable English. It ends when the transcript is traceable to the source audio, the translation fits the audience, and the output can be used in subtitles, documentation, or audit workflows.
Why Modern French Audio Translation Is a Two-Stage Process
Many organizations begin with the same question: can AI do audio French translation to English directly from the recording?
Technically, yes. Practically, the most reliable workflow is still two-stage. First, transcribe the French audio into an editable source transcript. Then translate that text into English. That separation gives you control over the part that usually breaks first: the source understanding.

Why the old approach didn't scale
For years, French-to-English audio work was expensive because it was labor-heavy. Someone had to listen, transcribe, translate, review, and often subtitle. That changed when multilingual speech models became practical.
A major turning point was OpenAI's Whisper in 2022, trained on 680,000 hours of audio in 97 languages, which helped make French-to-English audio translation a software workflow that can be delivered in minutes instead of days, as described in ElevenLabs' overview of French-to-English audio translation.
That shift matters because French and English are both high-resource languages in modern speech systems. In plain terms, models have seen enough real-world examples to support dependable speech to text to translation pipelines.
Why direct translation often causes avoidable errors
If a French speaker says a company name, a medical term, or a regional phrase, a direct audio-to-English system has to solve several problems at once. It has to identify the speech, infer punctuation, resolve ambiguity, and translate the meaning in one pass. When the recording is noisy, those errors compound.
A transcript-first process is easier to audit:
- You can inspect the source text before translation starts.
- Editors can fix names and jargon without relistening to the entire file.
- Teams can preserve speakers and timestamps from the beginning.
- Developers can version each stage as separate assets in a pipeline.
Practical rule: If the English output will be used in legal, healthcare, media, or customer operations, don't skip the editable French transcript.
This is also where broader AI literacy helps. If your stakeholders still treat these systems like magic, a clear explainer on what is a large language model helps frame what language models do well and where speech workflows still need structure around them.
What the production architecture usually looks like
The workflow many teams use today is straightforward:
- Ingest the French audio
- Run automatic speech recognition
- Review the French transcript
- Translate into English
- Export subtitles, documents, or structured data
If you want a deeper technical breakdown of the speech layer itself, this guide to how automatic speech recognition works step by step is worth reading before you design your workflow.
What works is boring in the best way. Clean transcription. Controlled translation. Human review where risk is high.
What doesn't work is treating business audio like a consumer demo.
Choosing Your French to English Translation Toolkit
Tool selection matters more than is often realized. The right choice depends less on marketing labels and more on three variables: audio quality, review requirements, and delivery format.
If you're translating a clean internal webinar for quick understanding, an all-in-one web app may be enough. If you're handling hearings, medical dictation, interviews, or on-the-ground reporting, you need editable transcripts and a workflow that keeps metadata intact.
The three tool categories that matter
Some teams overbuy. Others choose the fastest upload tool and then discover it can't support review, speaker tracking, or export requirements.
Here's the practical breakdown.
| Tool Type | Best For | Pros | Cons |
|---|---|---|---|
| All-in-one web translators | Quick internal understanding of simple recordings | Fast to start, low friction, no setup | Limited control, weaker audit trail, often poor fit for noisy or multi-speaker audio |
| Professional AI transcription and translation platforms | Business, media, legal, healthcare, and operations workflows | Editable transcript-first process, speaker labels, timestamps, export options | Requires review discipline, more steps than instant tools |
| APIs and SDKs | Product teams, large archives, automated pipelines | Full automation, custom integration, batch and streaming support | Needs engineering time, QA logic, and application-level orchestration |
What separates usable from unusable output
A key operational reality is that real-world performance drops when audio is accented, noisy, mixed-language, or domain-specific. That's why an editable transcript matters. Kapwing's discussion of French-to-English audio translation notes that production workflows still need human review and transcript editing before export.
That aligns with what teams see every day. The problem isn't only translation quality. It's whether the system can let you fix the source before translation errors harden into final output.
A rough translation can be good enough for discovery. It is not good enough for evidence, publication, or customer-facing documentation.
How I'd choose in common scenarios
Use a simple web tool if:
- The recording is clean: one speaker, little overlap, minimal jargon.
- The audience is internal: a manager just needs to know what was said.
- The output is disposable: no long-term archive or compliance need.
Use a professional platform if:
- Multiple people are speaking: interviews, meetings, panels, hearings.
- You need traceability: timestamps, diarization, editing history.
- The English output will be reused: subtitles, reports, case files, newsroom copy.
Use an API if:
- You process audio at volume: contact-center calls, media archives, research repositories.
- You need integration: CRM, CMS, DAM, case management, or custom apps.
- You want control: routing, fallback logic, metadata handling, and post-processing.
One option in the professional-platform category is Vatis Tech, which offers editable transcription, speaker diarization, timestamps, and export formats that fit this transcript-first workflow. It's one example of the kind of tool to consider when “instant translation” isn't enough.
For leadership teams trying to tie tooling decisions back to outcomes, this piece on delivering tangible business growth with AI is a useful reminder that AI projects create value when they fit operations, not when they just demo well.
The real trade-off
Fastest is rarely cheapest once rework starts.
If your team spends hours cleaning mistranscribed names, restoring speaker attribution, or manually rebuilding subtitles, the “simple” tool wasn't simple at all. The right toolkit is the one that reduces correction effort downstream.
Executing the Core Workflow From French Audio to English Text
A production workflow should feel predictable. That's the point. You want the same inputs to produce the same stages every time, so editors and developers know where to intervene.
The sequence below is the one I'd use for most audio French translation to English projects.
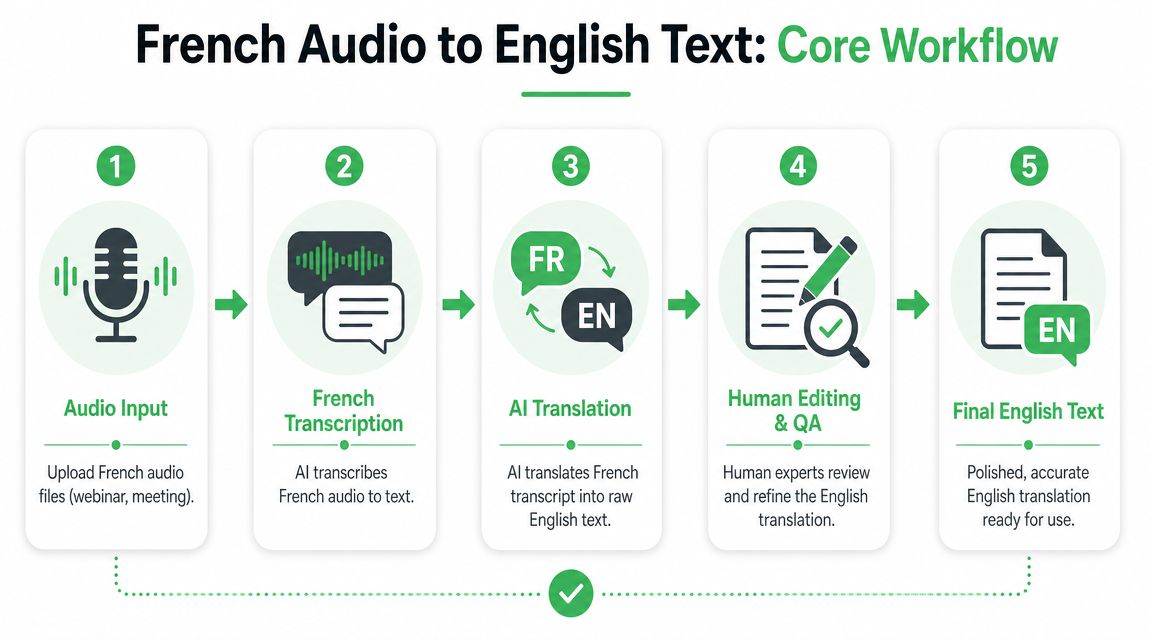
Step 1. Prepare the audio before upload
A surprising amount of translation quality is decided before any model runs.
Industry guidance emphasizes that transcription quality is the foundation of translation accuracy. Best practice is to use a quiet environment, a good microphone, and provide context such as glossaries or related materials to reduce ambiguity in technical, legal, or medical content, as explained in Motaword's guidance on translating French to English.
If the recording already exists and you can't improve capture quality, you can still improve the outcome by packaging context with the file.
Useful inputs include:
- Speaker names: especially for interviews, panels, and testimony
- Glossaries: product terms, legal phrases, drug names, acronyms
- Reference materials: agenda, slide deck, prior transcript, case summary
- Expected output style: plain English summary, subtitle-ready translation, verbatim legal rendering
Step 2. Generate the French transcript first
Don't translate the raw audio first. Generate the French transcript and inspect it.
In this context, a dedicated transcript editor proves its worth. A platform with time-synced playback lets reviewers jump directly to uncertain phrases instead of scrubbing manually through the whole file. If your team is still building that part of the process, this guide on transcribing audio to text is a practical reference.
Key things to check in the source transcript:
Named entities
Company names, locations, product lines, and people often break first.Acronyms and abbreviations
Spoken French abbreviations can be ambiguous without context.Speaker boundaries
If two people overlap, diarization may need correction.Numbers and dates
These often matter more than the surrounding sentence.
Fixing the French transcript before translation is usually faster than repairing broken meaning in the English version.
A short example makes this obvious. If the French source transcript incorrectly hears a drug name or a brand acronym, the English translation may look fluent while being substantively wrong. Fluency can hide source errors. That's why transcript review comes first.
Here's a useful visual walkthrough of the broader idea in action:
Step 3. Translate the cleaned transcript into English
Once the French transcript is stable, run translation on text, not raw speech.
This gives you cleaner sentence segmentation and more predictable handling of punctuation. It also makes it easier to localize for the target audience. For example, an English transcript for a U.S. compliance team may need plain terminology, while subtitles for a documentary may need to preserve more of the source tone.
At this stage, decide what “good” means:
| Output Goal | Translation Style |
|---|---|
| Internal review | Fast, readable, lightly edited |
| Broadcast subtitles | Concise, natural, time-aware |
| Legal or healthcare documentation | Conservative wording, terminology review, source traceability |
| Research archive | Faithful translation with metadata preserved |
Step 4. Keep metadata attached to the text
The professional difference isn't just better wording. It's preserving structure.
That means the English output should stay connected to:
- Timestamps
- Speaker labels
- Segment boundaries
- Original French source lines
Without that, reviewers can't verify disputed passages efficiently. Editors lose confidence fast when they can't click a line and hear the source moment behind it.
Step 5. Treat first-pass English as draft output
The first English pass is rarely final. It's a working draft that needs review against audience and use case.
For no-code users, that usually means editing in the platform UI. For developers, it means storing both the source transcript and translated output as separate objects, then routing flagged segments for review based on business rules.
That extra discipline is what makes the process reliable, not slow.
Mastering the Edit and Quality Assurance Pass
Most translation failures don't happen because the model is weak. They happen because nobody does the final pass with enough context.
Professional review has two layers. First, confirm the French transcript against the audio. Second, refine the English so it sounds correct to the target audience, not just mechanically translated.

Review the French before you touch the English
This step catches the expensive mistakes.
A practical benchmark isn't raw word-for-word output. It's end-to-end workflow quality, including transcript review before post-editing the English for terminology and audience fit, especially in broadcast and legal contexts, as noted in PrismaScribe's French-to-English translation guidance.
That means reviewers should listen for:
- Misheard proper nouns
- Merged or split speaker turns
- Incorrect punctuation that changes meaning
- Domain terms that ASR often normalizes incorrectly
A courtroom recording and a marketing webinar need different editorial behavior. In legal content, reviewers should be conservative and stay close to the source. In media content, they can smooth phrasing for readability if the meaning remains intact.
Then localize the English for humans
Literal translation is where a lot of “AI-looking” output comes from. French sentence structure often carries over awkwardly if nobody rewrites for English readability.
Good post-editing usually means:
- Cutting over-literal phrasing
- Resolving idioms into natural English
- Preserving tone when it matters
- Normalizing terminology across the full file
Editorial habit: Review line by line with audio playback available. If a sentence feels odd in English, check whether the source was ambiguous or whether the translation was too literal.
A practical QA checklist
I like using a short pass/fail checklist before export:
| QA Check | What to confirm |
|---|---|
| Source fidelity | The English reflects the corrected French transcript |
| Terminology consistency | The same term is translated the same way throughout |
| Speaker integrity | Quotes and statements stay attached to the right person |
| Timestamp usability | Segments still line up with source audio |
| Audience fit | Register is appropriate for the final use |
For team workflows, collaboration helps most when roles are distinct. One reviewer validates the source transcript. Another checks the English for meaning and style. When the same person does both under deadline, subtle errors slip through because the brain auto-corrects what it expects to hear.
What works is targeted review of the risky parts. Names, acronyms, legal phrases, medication names, and emotionally loaded statements deserve a second look even when the rest of the file seems clean.
Exporting for Subtitles, Documentation, and Compliance
The export step decides whether your translated asset is useful or just readable.
A lot of tools treat export as an afterthought. That's fine for casual use. It's a problem when the English output needs to go into a video workflow, a case file, an editorial archive, or a medical record.
Match the format to the job
Different outputs serve different teams:
- SRT or VTT: best for subtitles and captions
- TXT or DOCX: useful for reports, review packs, and searchable documentation
- JSON: best when developers need structured text, timestamps, speakers, or downstream parsing
If your team is deciding between caption formats, this comparison of VTT vs SRT is a practical place to start.
Metadata is part of the deliverable
One major gap in most coverage of French audio translation is the lack of attention to speaker identity and timestamps. That matters for broadcasters, courts, and healthcare teams that need auditable outputs rather than rough English summaries, as highlighted in Sonix's discussion of translating French audio to English text.
That changes how you should export.
For example:
- A newsroom needs timestamped quotes so producers can verify the exact moment a source said something.
- A legal team needs speaker attribution and source traceability so translated text can be checked against the recording.
- A healthcare team may need structured documentation where who said what matters as much as the wording itself.
If the output may be challenged later, export with the metadata intact the first time. Reconstructing speaker and timing information after the fact is painful.
Security and deployment also matter
Privacy requirements vary a lot by industry. Some teams are fine with a browser-based workflow. Others need stricter data handling, retention controls, or private deployment models.
When you evaluate platforms, check whether they support:
- Encrypted processing paths
- Access controls and workspace permissions
- Retention and deletion policies
- Private cloud or on-premise options when needed
The file format is only half the export decision. The rest is governance.
Integrating Translation with an API and SDK
If you're building this into a product or internal system, the transcript-first workflow becomes even more valuable. It gives your application clean checkpoints: ingest, transcribe, review, translate, export.
That's easier to debug than a single opaque call that returns English text with no trace of how it got there.
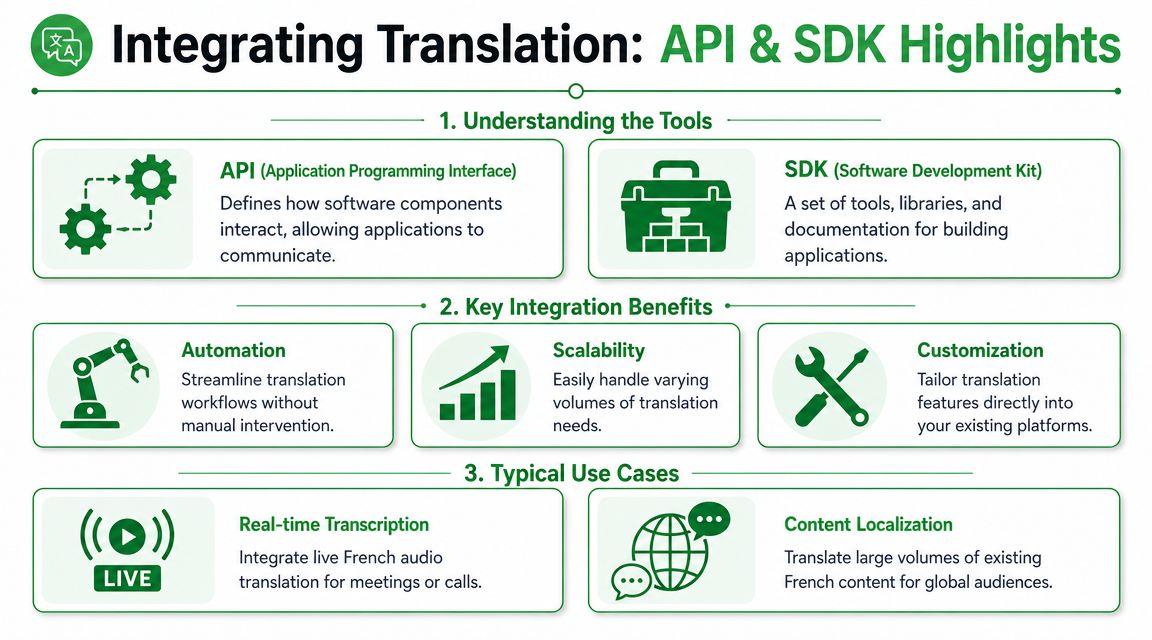
What developers usually need
Most product teams want some mix of these capabilities:
- Batch processing: submit recorded French audio files and receive transcript plus translation artifacts later
- Streaming workflows: support live meetings, calls, or events with low-latency transcript updates
- Custom vocabulary: improve handling for brand names, acronyms, and domain-specific terms
- Structured outputs: return timestamps, speakers, confidence signals, and translated segments in machine-readable form
The architecture choice is usually simple. Use batch for archives, compliance, and media libraries. Use streaming for support operations, live captioning, and event products.
A simple API pattern
The exact endpoint will vary by vendor, but the logic is usually the same: upload audio, request French transcription, review if required, then request English translation on the corrected transcript.
audio_file = open("french_meeting.mp3", "rb")job = client.transcriptions.create(file=audio_file,language="fr",diarization=True,timestamps=True,glossary=["product name", "internal acronym", "speaker surname"])french_transcript = job.get_transcript()edited_transcript = review_and_correct(french_transcript)english_translation = client.translations.create(text=edited_transcript["text"],source_language="fr",target_language="en",preserve_timestamps=True,preserve_speakers=True)export(english_translation, format="json")The important part isn't the syntax. It's the separation of responsibilities.
Keep the stages distinct in your system:
| Stage | What to store |
|---|---|
| Ingest | Original media file and metadata |
| Transcript | French text, timestamps, speaker labels |
| Review | Corrections, reviewer notes, version history |
| Translation | English text mapped to source segments |
| Export | Final files for UI, captions, or downstream systems |
That structure makes retries safer and QA much easier. It also lets you route only problematic segments to a human reviewer instead of blocking the whole file.
Frequently Asked Questions
Can AI handle regional French accents like Quebec French?
Sometimes well, sometimes not. Accent, dialect, recording quality, and speaker overlap all affect results. In practice, accented or code-switched audio should go through the transcript-first workflow so a reviewer can correct the French before translation.
What's the best way to translate noisy French audio?
Start by improving what you can control. If you're still recording, use a quiet room, avoid people talking over each other, and capture with a decent microphone. If the file already exists, supply speaker names, glossaries, and any context that helps disambiguate the source.
Is direct French audio to English translation ever good enough?
Yes, for quick internal understanding. If a product manager just wants the gist of a webinar, direct output may be fine. It's a poor fit when you need traceability, subtitles, legal defensibility, or polished English for publication.
Should I translate first or subtitle first?
Translate first from the corrected transcript, then generate subtitle files from the reviewed English. If you subtitle too early, every text correction creates timing rework.
Can I get live French-to-English translation for meetings or events?
Yes, many systems now support live or near-real-time workflows. But live translation has a different risk profile than file-based processing. There's less time for correction, so expectations should be clear: live output is useful for understanding in the moment, while the post-event transcript should still go through review.
What matters more, speed or accuracy?
That depends on the use case, but separating them generally leads to better decisions. Use fast draft output for discovery. Use reviewed transcript-first output for anything that becomes an artifact. That split keeps costs under control without pretending every file needs the same editorial effort.
How should no-code users think about this process?
Use a platform that lets you upload a French file, inspect the transcript, edit mistakes, then generate English from the corrected source. If you can't review the source transcript easily, you'll spend more time fixing hidden issues later.
How should developers think about this process?
Model it as a pipeline, not a single feature. Store the original audio, the French transcript, the edited version, and the English translation separately. That gives you observability, auditability, and cleaner retries when something fails.
If your team needs a practical way to turn French audio into editable transcripts, English translations, subtitles, and structured exports, Vatis Tech is worth evaluating. It fits the transcript-first workflow described above, which is what makes audio translation usable in real operations instead of just impressive in a demo.




