HOME / PRODUCTS /
SPEECH-TO-TEXT API
It's simple. We wanted to build the most accurate and fastest transcription software and we delivered on our promise. Find more data below.

TRUSTED BY HUNDREDS OF FAST-GROWING COMPANIES






Rated 4.9/5 by our users
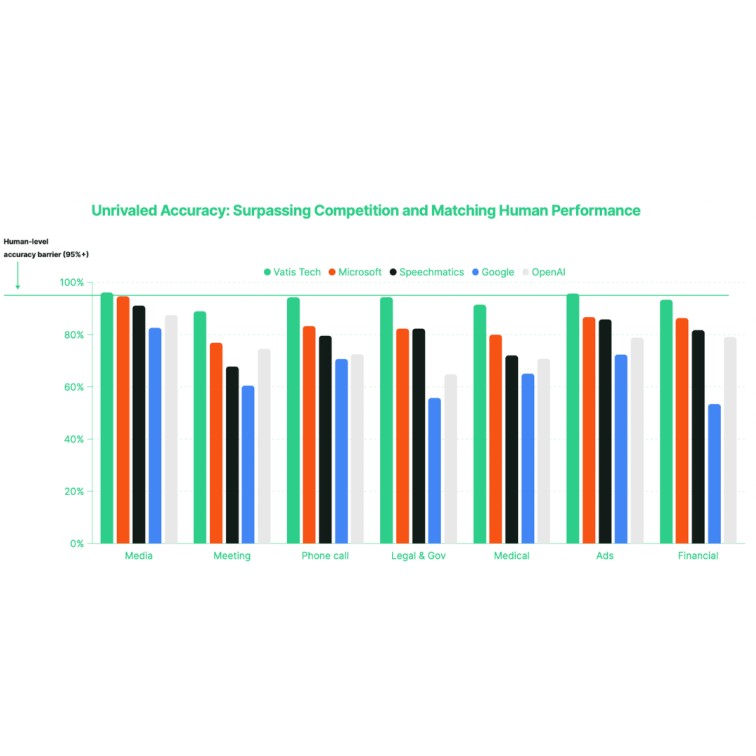
98%+ accuracy is not a marketing number. We benchmark our models datasets weekly. When we say 98%, we mean it. Our LLMs are trained on diverse audio (accents, background noise, crosstalk) because real conversations aren't recorded in a studio.
We've prepared a short video tutorial to showcase the seamless functionality of our speech analytics software:
Our API gives you 98%+ accuracy across 98+ languages, with speaker diarization, sentiment analysis, and real-time streaming baked in. Deploy in our cloud, yours, or on-premise. Your infrastructure, your rules.




What's in it for you?
Transcription with 98%+ accuracy in 50+ languages
Just test it. It's simply the most accurate.
AI-powered summaries, chapters, and translations
Upload any audio or video file and Vatis turns it into a searchable, editable transcript in minutes. Then use our AI to generate summaries, blog posts, social media captions, newsletters, and more.
Interview to article
Break the news before anyone else. Record the interview, we handle the writing and the news is up.
See more ways to save time with Vatis


What's in it for you?
Global Language Support. Transcribe in multiple languages with ease. Ideal for communication and data accessibility in international teams and multilingual content.
View supported languages
Language Code-Switch.
Detects and transcribes language changes in real time, even within the same sentence.
Security & Compliance
ISO 27001 certified. GDPR and LGPD compliant. SOC 2 Type II in progress. On-premise and private cloud deployment.
View supported formats
View all the features of our Speech-To-Text API


What's in it for you?
Global Language Support. Transcribe live audio in multiple languages instantly. Accurate, real-time results regardless of speaker location or language spoken.
View supported languages
<700ms Latency.
Built for speed. Achieves minimal latency of approximately 700 milliseconds. Perfect for live broadcasts, meetings and customer support.
Real-Time Insights.
Don’t just capture what’s said, understand it instantly. Get live summaries, intent tags, and smarter support triggers as conversations happen.
View all the features of our Real-Time Speech-To-Text API



What's in it for you?
Summarization and Sentiment Analysis.
Get instant, clear summaries, plus analysis of the sentiment behind spoken words. Understand the tone, intent, and what matters in a conversation.
Custom Vocabulary.
Add your own jargon, brand names, or technical terms. Vatis adapts to your world. No more awkward misreads or weird transcriptions.
Custom AI Prompts.
Use tailored AI prompts to shape the output. Make the API speak your language and adapt to the unique needs of any project or industry.
View all the features of our Audio Intelligence API

Read the documentation, try for free, tell us how it goes.
98%+ accuracy is not a marketing number. We benchmark our models datasets weekly. When we say 98%, we mean it. Our LLMs are trained on diverse audio (accents, background noise, crosstalk) because real conversations aren't recorded in a studio.
Broadcasting Transcription
when Transcribing hi-quality audio at Antena 3 CNN
Read Case Study
Media Monitoring
helps Observer.at to expand their media monitoring services and reinforce their technical leadership
Read Case Study
Medical Transcription
for Emerald Medical Center using our flexible, fully customizable speech-to-text solution
Read Case Study
Research & Interview Transcription
to Unlock Data-Driven Business Insights for Mediatel Data
Read Case Study
Podcast Transcription
helping The Vast & The Curious save costs for their podcasting needs.
Read Case Study
Legal Transcription
allows JURIDICE.ro to handle large volumes of data with ease.
Read Case Study
~5x faster than a human
Hours of transcription time are reduced to minutes for Mercury Reseach.
Read Case Study
Journalists and Newsrooms
allowing AGERPRES to provide more high-quality content in less time.
Read Case Study
Our robust automatic speech recognition (ASR) engine consistently achieves a speech-to-text accuracy exceeding 90%, and approaches an impressive 99% when transcribing high-quality audio—reaching a level of accuracy comparable to human transcription.
Accelerate high-volume transcription tasks with our efficient batch transcription API. Process multiple audio and video files simultaneously and receive accurate results in minutes.
Power real-time workflows with our real-time transcription API. Ideal for live broadcasts, streaming events, and interactive applications.

Simplify deployment with our flexible cloud-based solution. Rapid integration and smooth scalability, perfect for fast-moving teams.

Maintain maximum control with our on-premise deployment option. Ideal for security-sensitive applications and custom integrations.

Enhance your applications with our transcription services that support over 40 languages. Transcribe content in multiple languages and engage a global audience.
Break down language barriers with seamless translation. Convert your transcripts into 30 languages, boosting accessibility and content reach.

Eliminate manual language selection – our intelligent API automatically identifies spoken languages.

Understands more than 40 languages that can be spoken in the same audio input and switches between them in real time as the language changes in the audio.

Adapt transcription to your industry with custom vocabulary. Improve accuracy for specialized terminology, jargon, and proper nouns.
Easily add domain-specific terms to our models to ensure that your transcriptions are accurate and relevant. This feature is particularly beneficial for industries like legal, medical, and technical fields where specialized language is common.

Boost Transcription Accuracy by 10-20%. Fine-tune speech recognition for your unique audio conditions and terminology. Train custom models with your data for unmatched precision.
Our team collaborates with you to create models tailored to your unique needs, ensuring superior performance for niche industries and specialized audio environments.

Ensure clear transcripts with proper numeral formatting. Automatically structure numbers for easy comprehension of dates, currencies, and measurements.

Enhance transcript readability with automatic punctuation and capitalization. Produce professionally formatted text ready for analysis and sharing.

Control transcript output with optional profanity filtering and disfluency handling. Create polished results suitable for diverse audiences.

Identify who said what and when with accurate AI speaker labelling or channel-based labelling. Both batch and real-time transcription.

Pinpoint specific moments with word-level timestamps. Quickly navigate audio/video and verify context.

Assess transcription accuracy at a glance with confidence scores. Focus editing efforts on sections needing refinement.

18 audio and video file formats. Conveniently upload common audio and video formats for transcription.

Easily integrate transcripts into your workflow with flexible export options. Choose the format that best suits your analysis needs: json, txt, pdf, word, srt

Start fast with our clear and comprehensive API documentation. Quickly implement features and accelerate your development process.

Extract key insights with intelligent summarization. Quickly grasp the essence of lengthy transcripts.

Unlock customer sentiment through sentiment analysis. Gauge emotions and opinions expressed in audio content.

Automatically identify themes and topics within transcripts. Efficiently categorize and organize your content.

Protect privacy with PII (Personally Identifiable Information) redaction. Automatically detect and remove sensitive data.

Structure long recordings with automatic chapter generation. Improve content navigation and enhance user experience.

Understand the purpose behind interactions with intent detection. Ideal for analyzing customer support calls or user feedback.

Turn your transcripts into a knowledge base with our 'Ask Anything' feature. Easily search and retrieve relevant information from your audio and video content.

Veronica Tudor
Deputy Chief Editor, AGERPRESS

Can’t find the answer you're looking for? Reach out to our Support team.
Three things. First, real-time multilingual code-switching, our model automatically detects and switches between languages mid-conversation without configuration. Most competitors require you to pre-select a language. Second, built-in audio intelligence (sentiment, topics, intent, PII redaction) in a single API call, no separate services to stitch together. Third, true on-premise deployment for organizations that can't send data to the cloud. Oh, and of course, the highest accuracy of them all.
98-99%+ on clean audio across all supported languages .Custom vocabulary and custom models can improve accuracy by 10-20% for specialized domains.
Yes. 10 hours of free transcription or more. Contact us to understand the amount of hours you need for testing and you get them. The free tier includes all features: transcription, diarization, sentiment analysis, audio intelligence, real-time streaming, and all 50+ languages. No feature gating.
Yes. Vatis offers full on-premise deployment, the entire speech engine runs on your hardware. Zero data leaves your network. We also offer private cloud deployment in your AWS, GCP, or Azure environment. This makes Vatis the only speech-to-text API provider with cloud, private cloud, AND on-premise options.
Vatis Tech supports transcription in 98+ languages including English, Spanish, French, German, Italian, Portuguese, Dutch, Russian, Arabic, Japanese, Korean, Chinese, Hindi, Turkish, Polish, Romanian, Swedish, Danish, Norwegian, Finnish, Czech, Greek, Hungarian, Indonesian, Thai, Vietnamese, Hebrew, and many more. You can also translate transcripts into 50+ languages with one click.
Open a WebSocket connection to our streaming endpoint. Send audio chunks (PCM, WAV, or OGG). Receive partial and final transcript events in real-time with 420ms average latency. Speaker diarization and language detection work in streaming mode. See our streaming quickstart guide for code examples.
Yes. ISO 27001 certified. GDPR and LGPD compliant. SOC 2 Type II in progress. End-to-end encryption. On-premise deployment ensures PHI and PII never leave your infrastructure. Custom BAA agreements available for HIPAA-covered entities.
30+ formats: MP3, WAV, M4A, FLAC, AAC, OGG, AIFF, WMA for audio. MP4, MKV, AVI, MOV, WebM, WMV, FLV, MPEG for video. Files up to 5GB and 10 hours. Batch processing supports thousands of concurrent files.
A speech-to-text API converts spoken language from audio or video files into written text via a programmable interface. Developers integrate it into applications, products, and workflows. Vatis Tech's speech-to-text API goes beyond basic transcription, it includes speaker diarization, sentiment analysis, topic detection, PII redaction, and real-time streaming across 98+ languages.

With a little obsession on quality, we made Vatis fast, accurate, and actually enjoyable to use. Then decided to share it with the world.
Made with ❤️ and ☕ in Europe 🇪🇺
Powering transcribevideototext.com with transcription software and API.



