




TABLE OF CONTENTS
Experience the Future of Speech Recognition Today
Try Vatis now, no credit card required.
A hospital administrator usually doesn’t start by shopping for “medical speech recognition.” The primary trigger is more concrete.
A physician says charting is spilling into evenings. A nursing leader says documentation quality varies too much between shifts. IT hears that one pilot tool looked promising in demos but created more cleanup work in practice. Finance wants to know whether a new documentation system will reduce transcription spend, shorten turnaround, or add another subscription line.
That’s the right moment to look at medical speech recognition clearly. Not as hype, and not as magic. It’s a documentation tool that can help clinicians capture spoken information faster and turn it into usable records. But the return depends on details that buyers often underestimate: audio quality, specialty vocabulary, security controls, EHR fit, and how much editing users still have to do.
What Is Medical Speech Recognition
Medical speech recognition is software that listens to spoken clinical language and converts it into text that can be reviewed, edited, and stored in the patient record.
That sounds simple. In a hospital, it isn’t.
Clinical speech is dense with abbreviations, drug names, handoffs, interruptions, accents, and specialty terms. A surgeon dictating a post-op note doesn’t speak like a family physician in a routine follow-up visit. A nurse giving shift report doesn’t sound like a radiologist finalizing an impression. Medical speech recognition has to handle those differences well enough to be useful in real workflow.
A practical definition
For administrators, the most useful way to think about it is this:
Medical speech recognition turns spoken encounters, dictation, and reports into draft clinical documentation that staff can use faster than typing or manual transcription.
The goal isn’t just to “make text.” The goal is to create documentation that is:
- Fast to capture: Clinicians speak naturally instead of typing every detail.
- Easy to review: Staff can correct and approve notes without rebuilding them from scratch.
- Searchable and reusable: Text can move into the EHR, support coding, and be found later.
- Operationally reliable: The system has to work in busy rooms, across shifts, and under compliance requirements.
Where buyers often get confused
Many people lump several tools together under one label. They’re related, but they’re not identical:
- Dictation software captures one speaker and turns speech into text.
- Ambient documentation tools listen during a visit and produce a draft note from the conversation.
- Medical transcription workflows may combine speech recognition with human review.
- Clinical documentation platforms add structure, templates, and EHR integration.
Those differences matter because the implementation path is different for each one.
Why it matters now
Documentation burden affects throughput, clinician satisfaction, and record quality. Speech recognition addresses a problem that administrators see every day: too much time spent converting care into paperwork.
When it works, clinicians spend less effort on note creation and more effort on patient care. When it’s deployed poorly, the burden moves from typing to editing. That’s why decisions about accuracy, privacy, workflow design, and ROI matter more than vendor marketing language.
How Medical Speech Recognition Works
Most buyers don’t need the math. They do need a mental model they can use during product evaluation.
The simplest model is to think of medical speech recognition as a multi-step clinical documentation pipeline. One part listens. Another decides what words were said. Another interprets meaning in medical context. Another separates who spoke. Then the system turns all of that into something a clinician can sign.
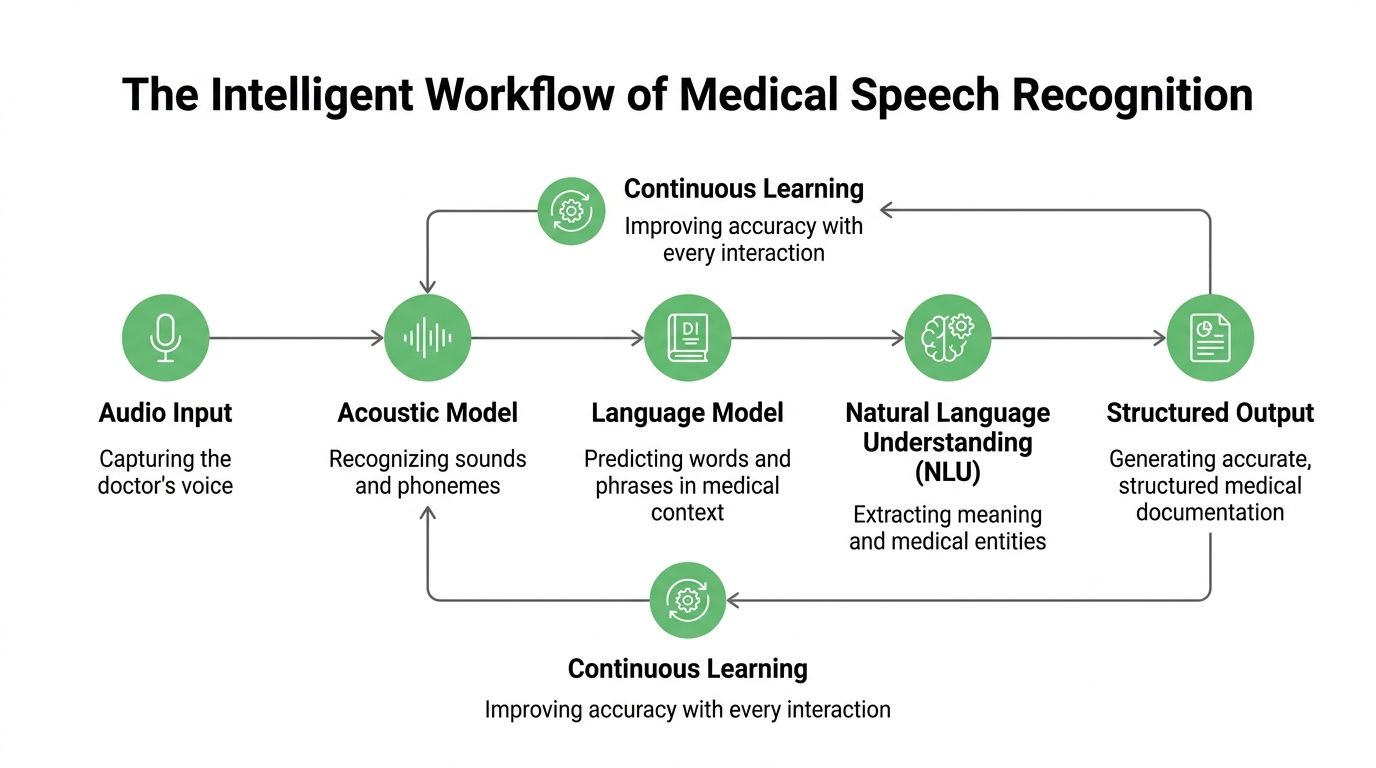
The core pipeline
A useful way to picture it is as a skilled documentation team working in sequence.
Audio capture
Everything starts with the sound signal.
That may come from a desktop microphone, mobile device, badge mic, room setup, call recording, or uploaded audio file. If the recording is weak, the rest of the system starts at a disadvantage.
Automatic speech recognition
This is the base engine, often shortened to ASR. It converts audio into words.
If a doctor says, “Start metoprolol and schedule follow-up,” ASR produces the raw transcript. On its own, that’s helpful but incomplete. Raw transcription doesn’t know which terms matter most clinically or where they belong in a note.
Language modeling
The next layer improves word choice using context.
A general speech engine might confuse similar-sounding terms. A medical-tuned language model is more likely to favor clinically plausible phrases, medication names, and specialty vocabulary. That’s why healthcare-specific training matters.
Natural language processing
This layer helps the system understand meaning, not just spelling.
It can identify diagnoses, medications, procedures, symptoms, and sections of a note. It may also organize a transcript into headings such as history, assessment, or plan. That’s the difference between a block of text and a workable draft document.
Speaker diarization
In many clinical settings, more than one person is talking.
Speaker diarization tells the system who said what. In a patient visit, that might separate clinician speech from patient speech. In a nursing handoff, it might help distinguish multiple staff members. That matters when the note should reflect the patient’s report separately from the provider’s assessment.
Why modern systems are different from old dictation tools
Medical speech recognition didn’t begin with today’s AI stack. The field has been evolving for decades.
In 1996, IBM launched MedSpeak, the first commercial continuous speech recognition product for medical applications, building on earlier research such as the DARPA SUR program from 1971-1976 and systems like Sphinx-II (1993). Early systems still had double-digit error rates, but they proved that continuous speech recognition could work in healthcare and helped reduce documentation turnaround times by 50% to 95.8% in fields like radiology, as described in this history of speech analytics and medical speech recognition.
What the infrastructure question looks like
Under the hood, modern speech systems also depend on serious compute. That matters more for developers and IT teams than for clinical leadership, but it affects latency, throughput, and deployment design.
Teams comparing infrastructure options sometimes review resources like this guide to best GPUs for machine learning when estimating what’s needed for model training, fine-tuning, or high-volume inference.
If you want a deeper technical walk-through of the transcription pipeline itself, this step-by-step guide on how automatic speech recognition works is a useful companion.
A buying mistake I see often: teams evaluate output samples without asking how the system got them. In production, audio capture, model tuning, and note formatting usually matter as much as the core recognizer.
Measuring Success With Accuracy and Key Metrics
Accuracy is the first question everyone asks. It shouldn’t be the last.
A vendor can claim strong performance, but what matters is whether the system performs in your rooms, with your speakers, under your workflow conditions.
Start with Word Error Rate
The most common metric is Word Error Rate, or WER.
In plain language, WER compares the transcript to a correct reference version and counts the mistakes. The formula is commonly understood as substitutions, deletions, and insertions divided by the total number of reference words.
For a hospital buyer, the practical meaning is simple. Lower WER usually means less correction work. But a single score can hide a lot.
A transcript can have a reasonable overall WER and still make dangerous mistakes on medications, diagnoses, or names. It can also perform well in a lab sample and poorly in a noisy nursing station.
For a detailed explanation of the metric itself, this guide on what WER means in speech-to-text is worth sharing with evaluation teams.
Why hospital environments change the result
Clinical audio is rarely clean.
In clinical environments, transcription accuracy can degrade by up to 30% from minor increases in microphone-to-speaker distance, and background noise increases of just 5-10 dB from HVAC, alarms, or hallway activity can significantly increase WER. Without domain-adaptive training and processing designed for noisy environments, WER can move from under 10% to 20-40% in typical noisy settings, according to this clinical ASR analysis on arXiv.
That single fact explains why buyers should test systems on real hospital audio rather than polished demo clips.
The four accuracy questions administrators should ask
Does it handle your acoustic environment
An exam room, emergency department, operating room, and nurse station all sound different.
Ask vendors to test on audio captured from your real devices and placement, not only on uploaded clean speech. A room microphone on a shelf won’t behave like a headset mic near the speaker.
Does it understand specialty vocabulary
A system may transcribe everyday English well and still fail on orthopedic implants, oncology regimens, or cardiology shorthand.
Ask how the platform handles custom vocabularies, specialty adaptation, and updates when terminology changes.
Does it perform across accents and speaking styles
This is one of the least discussed issues in purchasing conversations.
If your workforce includes multilingual or non-native speakers, accuracy testing should include them. Otherwise, the system may look acceptable in a pilot and fail during broader rollout.
Measure beyond accuracy alone
A hospital should track a small scorecard, not one number.
| Metric | Why it matters | Practical question |
|---|---|---|
| WER | Shows transcript error level | How much correction work remains? |
| Edit effort | Captures human cleanup burden | Are clinicians rewriting notes? |
| Turnaround time | Measures documentation speed | Are reports available sooner? |
| Adoption by role | Reveals real usability | Do physicians and nurses keep using it? |
| Section accuracy | Tests note usefulness | Are meds, history, and plan landing correctly? |
Later in an evaluation, it helps to watch a plain-language explainer before stakeholder meetings:
Don’t accept “high accuracy” as a complete answer. Ask where the system fails, who has to fix those failures, and how much time that cleanup takes.
Ensuring Security and Patient Privacy
If accuracy determines usefulness, security and privacy determine whether the deployment is acceptable at all.
Clinical speech contains protected health information. That includes names, dates, conditions, medications, and details that can identify a patient even when a transcript looks harmless at first glance. A hospital can’t treat speech recognition as just another productivity tool.
What compliance means in practice
In the United States, HIPAA governs how protected health information is handled. In Europe, GDPR shapes how personal data is processed, stored, and transferred.
For a speech recognition platform, the practical questions are straightforward:
- Where is the audio stored
- Who can access transcripts
- How is data encrypted
- Can the organization control retention
- Does the vendor support contractual and operational compliance requirements
A healthcare buyer should expect clear answers before any pilot touches live patient data.
The controls that matter most
Not every security feature has the same operational value. These are the ones administrators and compliance teams usually need to verify early.
Encryption in transit and at rest
This protects data while it moves through networks and while it sits in storage. If a vendor can’t explain both clearly, that’s a warning sign.
Access controls and auditability
Hospitals need to know who accessed which transcript and when. Role-based permissions matter because transcription data often crosses clinical, coding, and IT workflows.
PII redaction
Personally identifiable information redaction helps remove sensitive identifiers from transcripts used for downstream review, analytics, or development work. In healthcare speech systems, that can be the difference between a useful operational dataset and an avoidable privacy risk.
Deployment flexibility
Some organizations are comfortable with managed cloud deployments. Others require private cloud or on-premise setups because of internal policy, data residency, or risk posture.
Security review should happen before enthusiasm builds around a pilot. It’s much easier to approve a promising workflow than to unwind one that already touched patient data incorrectly.
What to ask a vendor
A short due-diligence checklist works well in early review:
- Compliance documentation: Ask for formal security and privacy documentation, not marketing summaries.
- Contract readiness: Confirm whether the vendor supports the contractual terms your legal and compliance teams require.
- Data handling detail: Request specifics on retention, deletion, redaction, and subprocessor use.
- Deployment options: Check whether cloud, private cloud, or on-premise models are available.
For teams reviewing vendor terms around data handling, a practical reference point is a formal data processing agreement.
Integrating Technology Into Clinical Workflows
Most medical speech recognition projects don’t fail because clinicians dislike speaking. They fail because the tool doesn’t fit the workflow around the speech.
That usually shows up as extra clicks, awkward copy-paste steps, note formatting problems, or one more inbox for clinicians to clear. A system can look accurate and still create resistance if it doesn’t reduce friction inside the EHR.
A study at one clinic found that although 87% of physicians viewed speech recognition positively, adoption stalled at 72% after six months because of editing burden and poor workflow fit with the EHR, as described in this study on physician adoption and workflow friction.
Cloud or on-premise
The first integration decision is often the deployment model.
| Factor | Cloud-Based (SaaS) | On-Premise |
|---|---|---|
| Setup speed | Usually faster to pilot and roll out | Often slower because internal infrastructure and approvals are involved |
| Maintenance | Vendor typically handles updates and service operations | Internal teams usually carry more operational responsibility |
| Control | Less direct infrastructure control | Greater control over environment and data handling |
| Scalability | Often easier to scale across sites and teams | Scaling depends on internal capacity planning |
| Security review | Requires strong vendor review and governance | May align better with stricter internal policies |
| Cost structure | Often subscription-oriented | Often heavier internal ownership and support requirements |
Neither model is automatically better. The right answer depends on security posture, procurement preference, IT staffing, and integration maturity.
Some organizations also bring in outside partners for infrastructure planning, networking, and managed rollout. If your team is assessing broader implementation support, these IT services for the healthcare sector give a useful overview of the kinds of operational help hospitals often need alongside new clinical systems.
Two workflow patterns that matter
Direct dictation
A surgeon finishes a procedure and dictates the post-op note immediately.
This workflow works best when clinicians want direct control over wording and timing. The system captures the dictation, drafts the note, and sends it into a review or sign-off path. Radiology and procedural specialties often prefer this pattern because the note is expert-led and concise.
Ambient documentation
A primary care physician speaks naturally during the visit while the system captures the conversation and creates a draft summary.
This workflow reduces keyboard time during the encounter, but it places more pressure on speaker separation, note structuring, and review design. If the draft lands in the wrong section or mixes patient statements with clinician assessment, trust drops quickly.
What good workflow integration looks like
The strongest deployments usually share a few traits:
- Minimal context switching: Clinicians shouldn’t jump between multiple windows just to complete one note.
- Clear draft status: Everyone should know whether text is raw transcript, structured draft, or final documentation.
- Specialty fit: Templates and fields should match the department’s real note patterns.
- Fast correction loop: Edits should improve the system or at least improve future output consistency.
The implementation question isn’t “Can the software transcribe?” It’s “Does the note reach the right person, in the right system, at the right stage, with less effort than today?”
Best Practices for Successful Implementation and ROI
The technical purchase is only half the project. The other half is operational discipline.
Hospitals that get value from medical speech recognition usually treat it as a workflow redesign effort with governance, training, and measurable outcomes. Hospitals that struggle often treat it as a software install.
Medical speech recognition systems can struggle with jargon, accents, and fast speech, and the editing burden can consume 20-30% of clinician time after transcription. With custom vocabulary training and better implementation practices, organizations can reduce that burden enough to achieve 40-60% reductions in overall documentation time and reach positive ROI within 6-12 months, according to this review of speech recognition advantages and implementation realities.
The implementation habits that usually separate winners from strugglers
Assign one accountable owner
Someone has to own rollout decisions across clinical leadership, IT, compliance, and vendor management.
Without clear ownership, pilots drift. Issues sit unresolved because each team assumes another group is handling vocabulary setup, user onboarding, or escalation paths.
Build specialty vocabularies early
A generic setup won’t match the language of cardiology, orthopedics, oncology, and behavioral health equally well.
Start with the departments where terminology is both frequent and high-value. If a platform supports custom terms, use them aggressively. That’s one of the most practical ways to reduce correction effort.
Train clinicians on realistic use
Training should focus on actual note completion, not product features.
Show clinicians how to review drafts, correct efficiently, and handle predictable failure cases. If users don’t know what the system is good at, they’ll either overtrust it or abandon it.
A rollout model that works
Many hospitals do better with a phased approach than a broad launch.
- Pick one contained use case: For example, post-visit dictation in a single specialty.
- Collect operational feedback: Measure edit burden, sign-off speed, and user retention.
- Adjust templates and vocabulary: Fix the known friction before expanding.
- Scale to adjacent workflows: Add another department or a second documentation pattern.
This isn’t slow. It’s controlled.
How to think about ROI without guessing
You don’t need invented spreadsheets to assess the business case. Start with a simple framework.
| ROI component | What to measure | Why it matters |
|---|---|---|
| Documentation time | Time to create and finalize notes | Shows labor impact on clinicians and support staff |
| Transcription cost | External or internal transcription spend | Identifies direct cost reduction opportunities |
| Adoption | Continued use by clinicians | Low use means the projected value won’t materialize |
| After-hours work | Whether charting shifts outside clinic time | Connects to burnout and retention concerns |
| Record quality | Correction rates and downstream queries | Shows whether documentation is usable operationally |
A finance team doesn’t need perfect precision on day one. It needs a disciplined baseline and a way to compare before and after.
What administrators should watch most closely
- Editing load: If clinicians are rewriting drafts, ROI erodes fast.
- Adoption by cohort: One enthusiastic department can hide broad resistance elsewhere.
- Operational handoffs: Coding, compliance, and record completion teams should feel less friction, not more.
- Governance cadence: Review performance regularly rather than waiting for complaints.
How Vatis Tech Powers Modern Healthcare Documentation
In real deployments, buyers need a system that addresses the issues that usually block scale: accent variability, specialty vocabulary, secure handling of patient data, and flexible integration.
A major challenge in medical speech recognition is weaker performance on non-native accents, particularly in diverse nursing teams where error rates can spike by 20-30%. The same source notes continued-use issues, with only 72% of physicians still using one system after six months, reinforcing how performance variability affects adoption, according to this PMC review on speech recognition barriers in diverse healthcare settings.
Matching platform features to hospital requirements
For decision-makers, the relevant question isn’t whether a platform sounds advanced. It’s whether the feature set maps to operational needs.
Vatis Tech provides high-accuracy speech-to-text transcription, support for many languages, speaker diarization, summaries, entity extraction, PII redaction, and API or SDK-based integration options. It also supports cloud, private cloud, and on-premise deployment models, which makes it easier to align the tool with different hospital security and architecture requirements.
Where that matters in practice
Diverse clinical teams
If your staff includes multilingual or non-native speakers, custom vocabulary and language support matter because generic transcription often breaks first on accents and local terminology.
Privacy-sensitive environments
PII redaction and controlled deployment options matter when transcripts may move through analytics, quality review, or development workflows.
EHR-connected documentation
API access matters when the goal isn’t just transcription, but movement of reviewed text into existing systems and templates.
The product checklist should map directly to your risk list. If accent variation, privacy, and integration are your biggest barriers, evaluate those first instead of starting with a polished demo transcript.
Conclusion and Frequently Asked Questions
Medical speech recognition can reduce documentation friction, speed up note creation, and improve how spoken clinical information becomes part of the record. But the technology only delivers value when the implementation matches healthcare reality.
For hospital administrators, the shortlist of decision criteria is clear. Evaluate the system on real audio. Treat workflow integration as a core requirement, not an afterthought. Involve compliance early. Measure edit burden, adoption, and turnaround, not just headline accuracy. And build the rollout around clinical use cases that staff will keep using.
That approach does two things. It protects the organization from expensive disappointment, and it gives clinicians a better chance of seeing the tool as help instead of extra work.
Frequently asked questions
How much does medical speech recognition cost
Pricing varies widely by deployment model, feature set, volume, and support requirements.
A simple dictation workflow won’t cost the same as an ambient documentation platform integrated into the EHR with custom security controls. Buyers should ask vendors to separate licensing, implementation, integration, support, and any costs associated with private or on-premise deployment.
Can it be used in real time during patient visits
Yes, many systems support real-time or near-real-time transcription.
The practical question is whether the workflow is direct dictation or ambient documentation. Real-time use is more demanding because speaker separation, note structure, and latency all matter during the encounter, not after it.
How should a hospital evaluate vendors
Use your own audio, your own specialties, and your own workflow scenarios.
Ask each vendor to demonstrate how the transcript is reviewed, corrected, and moved into the record. Involve clinicians, IT, compliance, and operations in the scorecard. A strong transcript sample is useful, but the approval and integration path usually determines real adoption.
What departments usually benefit first
Departments with high documentation volume and repetitive note patterns often make good starting points.
That could mean radiology-style dictation workflows, post-procedure notes, or structured outpatient encounters. The best pilot area is usually the one with enough volume to show value and enough consistency to support clean evaluation.
Will speech recognition eliminate human review
No. In healthcare, review remains important.
The goal is to reduce manual effort, not remove accountability. Even excellent systems should fit into a process where clinicians or authorized staff validate what becomes part of the record.
What’s the biggest implementation mistake
Buying for accuracy alone.
If the product doesn’t fit the EHR workflow, if users need too much editing, or if privacy review comes too late, the project can stall even when the underlying transcription engine is strong.
If you're assessing options for secure, flexible medical speech recognition, Vatis Tech is worth reviewing for teams that need API-driven transcription, custom vocabulary, PII redaction, and deployment choices that fit healthcare compliance requirements.




