




TABLE OF CONTENTS
Experience the Future of Speech Recognition Today
Try Vatis now, no credit card required.
A few seconds per note sounds minor until you multiply it across every visit, handoff, and chart correction in a hospital. Documentation friction acts like a slow tax on clinical operations. It pulls physician attention toward the screen, delays chart completion, and leaves coding, billing, and quality teams cleaning up gaps later.
Medical speech to text matters because it changes how documentation gets produced, not just how fast words appear on a page. A good system can shift note creation closer to the conversation itself, whether that means direct dictation, ambient capture, telehealth transcription, or speech routed into structured fields. That difference matters to hospital leaders trying to reduce overtime and improve throughput. It also matters to developers who have to make the tool fit the EHR, the microphone setup, the identity stack, and the reality of a busy clinic.
The practical question is not whether speech technology sounds impressive. The practical question is where it produces measurable value first. For one organization, that may be faster turnaround for radiology or emergency documentation. For another, it may be reducing after-hours charting in ambulatory care. The right starting point depends on workflow bottlenecks, note types, specialty vocabulary, and how much change management the clinical team can absorb.
Medical speech to text also is not a single buying decision. It is closer to a program of choices: capture method, specialty adaptation, privacy controls, EHR integration, user training, and success metrics. That is why the strongest evaluations look beyond transcription accuracy alone. Clinical leaders need to know what will happen to note quality, turnaround time, staff acceptance, and return on investment after the pilot. Developers need to know what data enters the system, how corrections train it, and where failures will surface in production.
This guide approaches medical speech to text as an implementation and decision problem, not just a definition. The goal is to help you choose where to start, what to test, what to protect, and how to judge whether the system is reducing documentation burden rather than relocating it.
The End of Clinical Documentation Overload
The scale of this shift is clear from the market activity noted earlier. Medical speech to text is no longer a pilot-category purchase for a few heavy dictation specialties. Health systems are treating it as a documentation operations decision because the cost of manual charting shows up across staffing, turnaround time, clinician retention, and patient experience.
Clinical documentation overload starts like a local workflow irritation and ends up behaving like a hospital-wide bottleneck. A delayed note slows coding. A rushed note increases correction work. A physician who finishes charts at night is not just losing personal time. The organization is absorbing hidden labor cost, slower billing readiness, and a higher risk of incomplete documentation.
That is why the practical question is not whether clinicians like dictating. The practical question is where speech to text removes the most expensive friction first.
For a hospital administrator, this usually comes down to three measurable areas. How quickly notes are completed. How much after-hours documentation is reduced. How much downstream rework is avoided in coding, quality review, and revenue cycle. For a developer or product owner, the focus is slightly different. Where does speech capture enter the workflow, how often do users need to correct output, and does the tool reduce clicks or shift cleanup to another screen?
A good way to frame it is to compare documentation workflows to supply chains. If one step is slow, every team after it waits. Clinical notes feed billing, care coordination, compliance review, prior authorization, and follow-up communication. When note creation depends on typing, copy-paste, or delayed transcription, the entire chain moves more slowly.
What this changes in practice
The operational value of medical speech to text usually appears in a few repeatable patterns:
- Less keyboard time for clinicians: Speaking is often faster than typing for narrative sections, especially for assessments, histories, and procedure notes.
- Notes completed closer to the encounter: That reduces end-of-day backlog and lowers the chance that details are forgotten or documented from memory hours later.
- Cleaner handoffs to downstream teams: Once dictation becomes editable text inside the workflow, coding, review, search, and audit processes can begin sooner.
- More realistic scaling for high-volume services: Emergency care, radiology, ambulatory clinics, and telehealth programs often see value first because documentation volume is already high.
The implementation lesson is simple. Evaluate medical speech to text as documentation infrastructure, not as a convenience feature.
Organizations that get a return usually begin with one costly bottleneck. A primary care group may target pajama-time charting. A radiology department may target report turnaround. A telehealth team may target duplicate entry from recorded visits into the EHR. Starting with a defined workflow makes it easier to set success metrics, gain clinician trust, and decide whether the system should expand.
That matters because speech to text does not eliminate documentation work by itself. It changes where the work happens. If the output still requires heavy editing, if specialty terms are missed, or if the text lands awkwardly in the EHR, the burden has only been redistributed. The strongest early programs measure more than recognition accuracy. They track note completion time, correction rates, clinician adoption, and the effect on downstream teams.
Used well, medical speech to text reduces drag across the documentation chain. Used poorly, it becomes another layer clinicians have to manage. The difference usually comes from choosing the right first use case, setting realistic workflow goals, and treating adoption as an operational project rather than a software switch.
How Medical Speech to Text Technology Works
Medical speech to text works best when you think of it as a highly specialized medical translator. It doesn’t just hear sounds. It has to recognize speech, interpret clinical context, and choose the right term among many similar-sounding possibilities.
A general consumer voice assistant can do fine with “set a timer” or “call home.” Clinical speech is harder. A doctor may speak quickly, use acronyms, switch between drug names and anatomy, correct themselves mid-sentence, and dictate in a noisy hallway. That’s why medical systems need more than generic speech recognition.
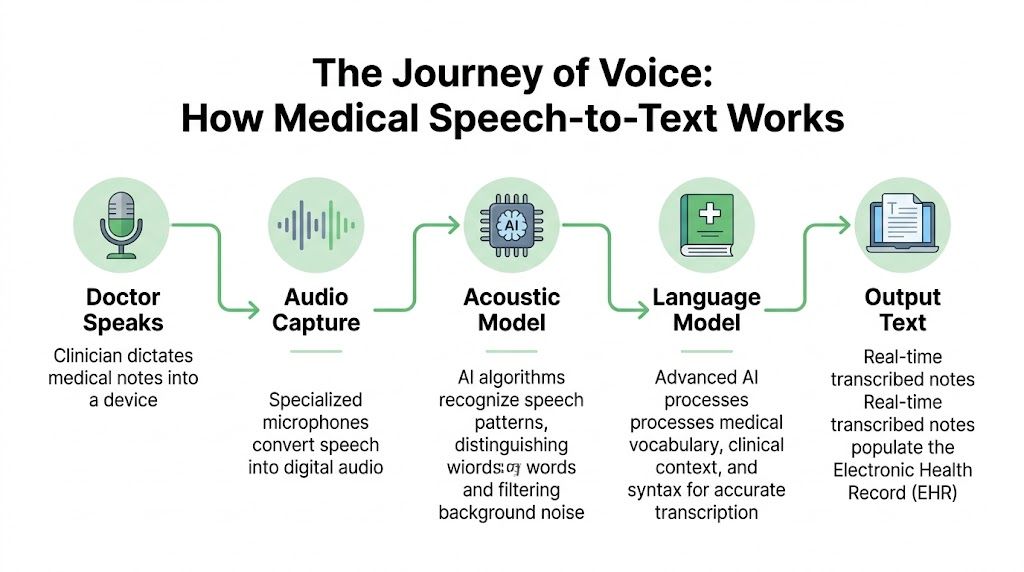
Step one recognizes the sounds
The first layer is automatic speech recognition, often shortened to ASR. This part converts audio into probable words. It has to deal with accents, room noise, microphone quality, interruptions, and speed.
If a clinician says “The patient takes metformin twice daily,” the ASR layer is responsible for hearing the sounds correctly in the first place. If it hears “met for men,” the rest of the pipeline starts with a bad input.
Step two interprets the meaning
The second layer adds natural language processing, or NLP, enabling the system to begin using context. It helps decide whether “discharge” refers to a patient leaving the hospital or a symptom. It also helps with punctuation, formatting, sentence boundaries, and phrase interpretation.
In medicine, context matters more than people expect. “Negative for chest pain” and “chest pain” are very different chart entries. A strong medical speech to text system needs to preserve that distinction reliably.
Step three uses a medical language model
The biggest difference between consumer tools and clinical tools is the domain-specific language model. This is the part trained to understand medical vocabulary, shorthand, specialties, and common documentation patterns.
That model should recognize terms such as medication names, procedures, abbreviations, and specialty-specific phrasing. It should also know that the language in radiology sounds different from psychiatry, and psychiatry sounds different from emergency medicine.
A practical implementation often includes:
- Medical vocabulary support: Drug names, anatomy, procedures, diagnoses, and abbreviations.
- Context-aware formatting: Dosages, punctuation, and note structure.
- Speaker-aware handling: Better separation between physician, patient, and staff voices in conversations.
A good medical model doesn’t just transcribe words. It reduces the chance that clinically important words are the ones that get missed.
What happens after transcription
In a production workflow, transcription is only the beginning. Many users want the text to go somewhere useful. That may include the EHR, a queue for human review, a coding workflow, or a summarization layer that turns a transcript into a draft note.
For administrators, this means the buying decision shouldn’t stop at “How accurate is the transcript?” It should include “What happens next?” For developers, it means choosing APIs and SDKs that support formatting, speaker separation, redaction, and structured outputs, not just raw text.
Transforming Patient Care with Key Applications
The strongest use cases for medical speech to text aren’t abstract. They show up in ordinary clinical moments where typing gets in the way.

Direct dictation into the chart
A common starting point is simple dictation. A physician speaks an assessment and plan into a phone, desktop mic, or secure mobile app, and the text appears in the note template. That reduces the stop-start rhythm of typing between every sentence.
This works especially well in specialties where clinicians already think out loud in structured language. Radiology, pathology, orthopedics, and primary care often fit that pattern. The gain isn’t just speed. It’s less friction between the clinical thought process and the documentation task.
A hospital IT team evaluating this use case should ask a narrow question first: where are clinicians already dictating informally into personal devices, voicemail, or delayed transcription channels? That’s often the easiest place to formalize a compliant workflow.
Ambient scribing during visits
Ambient documentation is the use case that gets the most attention because it changes the visit dynamic. Instead of the doctor pausing to document, the system listens during the conversation and drafts a note in the background.
In primary care, that might mean the clinician keeps eye contact while discussing symptoms, medication changes, and follow-up plans. After the visit, the doctor reviews a draft rather than building the note from scratch.
This approach is promising, but it needs careful workflow design. Teams have to decide:
- Who reviews the draft: The clinician, a scribe, or a support team.
- What gets captured: Full encounter transcript, note summary, or both.
- How consent is handled: Patients should know when audio is being used and how it’s protected.
For mental health and behavioral care, nuance matters even more. If you’re exploring virtual visit workflows, this guide to psychiatric telemedicine is useful context because it highlights how remote encounters change documentation habits and patient expectations.
A vendor page such as medical speech to text solutions for healthcare teams can also help technical buyers compare how transcription products position real-time capture, review, and editing features for clinical settings.
Telehealth and remote consultations
Telehealth creates a different transcription challenge. Audio quality varies. People talk over each other. The patient may join from a car, kitchen, or shared living space. Clinicians still need a usable record.
That’s where real-time transcription helps beyond note creation. It can support follow-up summaries, quality review, and searchable records of what was discussed. A support team can also use transcripts to verify medication instructions or identify points that need clarification before sign-off.
Here’s a short demonstration of medical speech workflows in action:
Hands-free use in sterile or busy environments
In operating rooms, procedure rooms, and other hands-busy environments, voice is more than a convenience. It can be the only practical input method. Clinicians may need to log observations, mark events, or control certain functions without breaking sterile technique.
Even outside surgery, hands-free workflows matter. Emergency staff, home health clinicians, and rounding teams often document while moving. A system that lets them capture information immediately can prevent details from being lost and reduce later reconstruction from memory.
Clinical value often comes from the smallest avoided delay. If a note starts during the encounter instead of after it, the whole downstream process gets cleaner.
The Critical Need for Medical Domain Adaptation
A transcription system can look accurate in a demo and still fail in production for one simple reason. Clinical language is its own operating environment.
Hospital buyers often learn this late. A vendor handles clean dictation well, then accuracy drops in live use because the system was built for general speech first and medicine second. The same MedASR documentation cited earlier notes that general-purpose ASR can struggle badly with clinical speech, while models trained on medical data perform better. It also describes training on thousands of hours of de-identified physician dictations across specialties. That distinction matters because healthcare speech is not just a bigger vocabulary problem. It is a context problem.
Why clinical speech breaks generic models
A general speech engine expects everyday patterns. Clinical speech compresses meaning into shorthand, acronyms, brand names, anatomy terms, lab values, and half-finished phrases spoken at speed. One sentence may contain plain English, Latin-derived terminology, and a dosage instruction, all under time pressure.
The result is predictable. Errors cluster around the words that matter most.
“MS” may mean multiple sclerosis, morphine sulfate, or mitral stenosis. “Negative” may describe a lab result, a symptom review, or a pregnancy test. A model that misses this context creates extra review work for clinicians and raises the risk of incorrect notes entering the chart.
Word Error Rate helps quantify the problem, but leaders should translate it into operational terms. A low-value mistake changes “the” to “a.” A high-value mistake changes a drug name, dosage, laterality, or diagnosis. Those are not equal errors. They drive different levels of rework, delay, and clinical risk.
What domain adaptation actually involves
Medical domain adaptation works like training a new staff member for a specialty clinic rather than handing them a dictionary on day one. Vocabulary matters, but pattern recognition matters more.
A healthcare-ready system usually combines several layers:
- Medical speech training data: Real clinical audio and transcripts, not just consumer speech with medical terms added
- Context-aware language models: Better prediction of which terms belong together in a cardiology note, radiology read, or behavioral health encounter
- Local customization: Provider names, facility names, referral partners, service lines, and common medications used in your organization
- Structured post-processing: Rules for dosages, punctuation, note sections, abbreviations, and formatting expected by downstream systems
For development teams, customized speech models for specialized vocabulary can be useful when a workflow includes uncommon medication names, local clinician directories, or specialty shorthand that broad models often miss.
Why this matters by specialty
Domain adaptation is not one decision. It is a series of decisions about where precision has the highest return.
Radiology benefits from correct anatomy, measurements, and comparison phrasing. Emergency care needs reliable performance under noisy, interrupted conditions. Behavioral health requires strong handling of conversational speech and nuanced wording, which can directly affect documentation quality and patient care in mental health. Each specialty places stress on the model in a different way.
That is why a single headline accuracy claim is not enough.
Questions that expose real readiness
A stronger evaluation process sounds less like “What accuracy do you claim?” and more like this:
- Which specialties were included in validation?
- Was performance measured on live encounters, dictation, or both?
- How does the model handle local terms and provider names?
- What is the correction workload for clinicians after first-pass transcription?
- How often does the vendor retrain or tune models for changing terminology?
These questions get closer to ROI. If a system saves five minutes on easy notes but adds three minutes of cleanup on complex ones, the business case weakens fast. If adaptation reduces correction time across high-volume specialties, adoption usually improves because clinicians feel the difference immediately.
If a vendor cannot explain how their system handles medical terminology, specialty variation, and local vocabulary, you are evaluating a generic transcription product with healthcare packaging.
The practical goal is not perfect transcription. It is dependable clinical documentation with a correction burden low enough that clinicians keep using it, compliance teams trust the output, and developers can integrate it into real workflows without constant exception handling.
Navigating Security and HIPAA Compliance
Security review is often where a medical speech-to-text project gets approved or stopped. That makes sense. A single audio file can contain diagnoses, medication names, dates of service, insurance details, and direct identifiers, which means the risk profile is closer to an EHR workflow than to ordinary voice software.
Clinical leaders should evaluate the transcription pipeline the way they would evaluate medication handling in a pharmacy. You do not only ask whether the medication is accurate. You ask who can access it, where it is stored, how it is tracked, and how it is disposed of. Speech data needs the same discipline from capture through deletion.
What procurement and security teams should verify
Start with the full lifecycle of the audio and transcript. A vendor should be able to explain each control in plain language, then back it up in security documentation.
- Encryption in transit: Audio and text should be protected as they move between devices, networks, APIs, and storage systems.
- Encryption at rest: Stored recordings, transcripts, backups, and logs should remain protected after processing.
- Access controls: Role-based permissions should determine who can listen, edit, export, or delete files.
- Audit logging: Security teams need records of who accessed PHI, when they accessed it, and what action they took.
- Redaction and de-identification support: Secondary uses such as QA, analytics, or model testing may require removal of identifiers from transcripts.
- Data retention and deletion policies: The vendor should define how long audio and text are kept, where they are kept, and how deletion requests are handled.
- Contract terms: Legal teams should review BAAs, subprocessor disclosures, breach notification terms, and cross-border data handling.
As noted earlier, the MedASR material references baseline protections such as TLS 1.2+ and AES-256. That is a starting point, not a compliance verdict. HIPAA review also depends on identity management, auditability, retention settings, incident response, and the way your team configures the product.
Behavioral health adds another layer of scrutiny. Sessions can include highly personal disclosures, family details, and crisis-related information that patients expect to stay tightly controlled. That is one reason organizations expanding online psychiatry often review consent language, transcript visibility, and storage policies before they approve broader rollout.
On-premise and cloud trade-offs
The hosting decision is usually about operational fit, not ideology. Hospitals sometimes assume on-premise deployment is safer because the servers are under local control. In practice, that only helps if the organization can maintain patching, monitoring, access reviews, backup protection, and incident response at the same standard the vendor can provide.
| Factor | On-Premise Deployment | Cloud Deployment (SaaS/PaaS) |
|---|---|---|
| Data control | Direct infrastructure control | Vendor-managed infrastructure within agreed controls |
| Implementation speed | Slower setup and validation | Faster to pilot and expand |
| IT burden | Internal teams handle updates, monitoring, and uptime | Vendor handles more day-to-day operations |
| Customization | Useful for tightly controlled internal environments | Useful for API-based rollout across sites and teams |
| Scalability | Expansion requires internal capacity planning | Capacity usually scales faster |
| Budget model | Often fits capital purchase processes | Often fits subscription or usage-based budgets |
| Security review | Can align with strict hosting rules | Can work well if contracts, audit logs, and access controls are clear |
A practical question helps here: which team will own security operations after go-live? If your internal team is already stretched, on-premise control can turn into delayed patches, incomplete logging reviews, and longer response times when issues appear.
Before signing, legal and compliance teams should review the vendor’s data processing agreement for enterprise transcription services. Do that before a pilot expands. It is much easier to set retention rules, subprocessor expectations, and deletion obligations early than to clean them up after clinicians start relying on the system.
Review the entire chain of custody for PHI. Capture, transmission, processing, storage, access, export, and deletion each create their own compliance obligations.
The business impact is straightforward. Strong security controls reduce legal exposure, shorten procurement cycles, and make it easier to scale from one department to many. Weak controls do the opposite. They slow deployment, trigger rework, and can erase the time savings that made the project attractive in the first place.
Integrating STT into Existing Clinical Workflows
Integration is where promising pilots often stall. The transcript itself may look good, but if clinicians have to copy and paste text manually, launch a separate app, or wait too long for results, adoption drops fast.
Start with one workflow, not one platform
The cleanest implementation plan begins with a single workflow decision. For example:
- Front-end dictation into an existing EHR field
- Ambient capture that produces a draft note for review
- Telephony or telehealth transcription for remote encounters
- Back-office transcription of uploaded audio files
Each has different technical requirements. Front-end dictation needs low-latency text streaming into a visible interface. File-based transcription can tolerate more delay if formatting quality is high. Ambient workflows need speaker handling, reliable segmentation, and careful review logic.
Why latency matters
For real-time clinical work, delay changes behavior. If a physician pauses after every phrase waiting for text to catch up, dictation stops feeling natural. If a telehealth transcript lags too far behind, support workflows lose their usefulness.
Telnyx’s medical STT guidance makes the threshold concrete: medical speech-to-text systems must achieve sub-200ms latency for real-time clinical workflows so they don’t disrupt natural dictation flow, and that performance depends on architecture that colocates telephony infrastructure with domain-adapted inference to minimize network delay in Telnyx’s overview of speech to text for medical use.
Common integration patterns
Organizations often implement medical speech to text through APIs or SDKs. The practical pattern looks like this:
- Capture audio from browser, mobile app, phone call, room microphone, or dedicated dictation device.
- Stream or upload it to the transcription service.
- Receive text events in real time or as a completed result.
- Apply review logic such as speaker labels, formatting, or redaction.
- Write the result into the EHR, document management system, or internal application.
Developers usually run into the same issues:
- Legacy EHR constraints: Some systems don’t expose modern APIs for writing structured text back into the chart.
- Authentication complexity: Clinical apps often require strict user identity and session handling.
- Review requirements: Many organizations want draft text separated from signed documentation.
- UI friction: Even a strong engine fails if the interface makes corrections painful.
A workable rollout sequence
A practical rollout often follows this order:
- Choose one department: Pick a team with repetitive documentation patterns and willing clinical champions.
- Define the target note type: History and physical, progress note, discharge summary, consult, or telehealth record.
- Test with real audio: Include noise, accents, crosstalk, and the actual devices clinicians use.
- Measure correction effort: Accuracy matters, but so does the time clinicians spend fixing output.
- Decide the review path: Real-time sign-off, assistant review, or queue-based validation.
The best technical implementation is the one clinicians barely notice. Speech in, text appears, review is quick, and nothing about the process feels fragile.
If your build requires custom applications, prioritize vendors with solid API docs, event handling, and sandbox access. If your environment is EHR-heavy and customization-light, integration support may matter more than model features.
Evaluating Vendors and Calculating ROI
Clinical documentation can consume hours each week for a single physician. That is why vendor evaluation should start with an operational question, not a feature question: where will speech to text remove enough work to justify the cost, implementation effort, and change management?
A useful way to frame this is simple. Buying medical STT is less like buying office software and more like redesigning a small part of your revenue cycle and clinician workflow at the same time. If the transcript is accurate but review is clumsy, the return disappears. If pricing looks attractive but notes still close late, the organization has saved little.
What ROI actually includes
Direct transcription savings matter, but they are only one line in the model. A stronger ROI case looks at what changes before, during, and after note creation.
- Clinician time returned: Less typing, less pajama-time charting, and less cleanup after dictation.
- Faster documentation completion: Notes close earlier, which can help coding, billing, and care coordination happen sooner.
- Lower correction effort: Better first-pass output reduces editing time and frustration.
- Workflow consistency: Standardized voice capture reduces side-channel workarounds such as personal apps or delayed dictation.
- Staffing flexibility: Work can shift from manual transcription toward review, exception handling, and quality control.
One common budgeting mistake is focusing too hard on cost per minute. In practice, a cheap engine with poor trust behaves like a copier that jams every fifth page. The sticker price looks fine. The wasted staff time does not.
Build a simple internal business case
A finance-ready business case does not need complex formulas. It needs numbers your clinical, IT, and operations teams agree are real.
| ROI question | What to examine |
|---|---|
| Where is documentation slowing care or operations? | Note completion delays, manual transcription queues, after-hours charting, telehealth documentation gaps |
| Who spends time correcting or re-entering text today? | Physicians, nurses, scribes, transcription staff, coding teams |
| What review process is acceptable? | Full clinician review, assistant review, exception-only review |
| What implementation costs are real? | Integration work, security review, training, support coverage, device changes |
| What outcome would justify rollout? | Faster note closure, lower correction effort, stronger clinician adoption, reduced outsourcing |
Hospital leaders often find that the best starting point is one note type in one department. That makes the math easier. You can compare current turnaround time, correction effort, and staffing costs against the pilot state without guessing across the whole enterprise.
Accuracy benchmarks should be concrete
Accuracy claims are easy to inflate and hard to compare. Ask each vendor to define accuracy the same way, on the same kind of audio, with the same review standard.
Speechmatics offers a useful example of the level of detail buyers should request. In its medical STT announcement, the company described real-world medical accuracy results and reported fewer clinical term errors relative to competitors in its testing, according to Speechmatics’ medical STT announcement. You do not need every vendor to publish identical benchmarks. You do need each one to show performance on clinical speech, medical terminology, and realistic recording conditions.
Ask follow-up questions that expose implementation risk:
- What audio was used for testing?
- Were speakers clinicians, patients, or both?
- Was the output measured before or after human correction?
- How did the model perform on specialties relevant to your organization?
- What happens to accuracy in noisy rooms, telehealth calls, or accented speech?
Those answers matter more than a headline percentage.
A practical vendor checklist
Use a checklist tied to operational fit and downstream cost.
- Medical validation: Can the vendor explain performance on real clinical audio and medical vocabulary?
- Deployment options: Does the hosting model fit your data handling requirements?
- Security posture: Are encryption, access controls, audit logs, and redaction features documented clearly?
- Integration maturity: Are APIs, SDKs, webhooks, and implementation docs ready for production use?
- Review workflow support: Can clinicians or staff edit and approve output quickly?
- Specialty fit: Can the system handle your note types, abbreviations, and terminology?
- Support model: Is there enterprise support for rollout, troubleshooting, and adoption?
If you are comparing API-driven tools, Vatis Tech is one option in the market. It offers speech-to-text APIs, SDKs, custom vocabulary support, and multiple deployment approaches for teams building healthcare transcription workflows. Evaluate it the same way you would evaluate any vendor: with your audio, your review process, your integration constraints, and your security requirements.
Buy for week-six behavior. If clinicians still trust the output after the pilot novelty wears off, the project has a real chance of producing return.
What to request in a pilot
A serious pilot should feel like a small production test, not a polished demo. The goal is to learn whether the tool changes real work.
Ask for:
- Testing with your own audio
- A defined note type or workflow
- A clinician review group
- An agreed success rubric
- A security and procurement path that will still hold after the pilot
That structure helps clinical leaders answer the question procurement really cares about: not whether the software can transcribe speech, but whether it can reduce documentation burden at a cost and effort level the organization can support.
Frequently Asked Questions About Medical STT
Is real-time streaming as accurate as batch transcription
Not always. This is one of the most important unresolved buying questions. Speechmatics has pointed out that real-world accuracy for streaming versus batch processing remains a critical evaluation point, and older benchmarks showed 38 to 65% error rates without custom training in clinical speech, as described in Speechmatics’ discussion of real-time clinical transcription. In practice, you should test both modes with your own audio and correction workflow.
How do strong systems handle accents and noisy rooms
They don’t solve the problem with one trick. They combine better microphones, acoustic modeling, medical vocabulary support, and workflow design. A strong vendor should be willing to test speech from your clinicians, your devices, and your noisy environments rather than relying on polished samples.
Can medical speech to text do more than create transcripts
Yes. It can support structured note drafting, speaker separation, redaction, and downstream automation. The key is whether the product outputs usable text and metadata in a form your systems can consume. Many organizations get the most value when transcripts feed review, coding, search, or summarization workflows rather than sitting as plain text alone.
What’s the biggest mistake during evaluation
Treating all “accuracy” claims as comparable. They aren’t. Ask what kind of audio was tested, whether the model was trained on medical speech, and how much human correction is still required before the note is clinically usable.
If you’re evaluating medical speech to text for a hospital, clinic, or healthcare product, Vatis Tech is worth a look as one option for teams that need transcription APIs, real-time processing, customizable models, and flexible deployment paths. The most useful next step isn’t a broad demo. It’s a focused pilot with your own audio, your own note types, and a clear review workflow so you can judge real fit quickly.




